
互联网爬虫即起此用途,它是搜索引擎系统中很重要也根基础的构件。排名里主要介绍与互联网爬虫有关的技术,尽管爬虫技术经过几十年的进步,SEO整体框架上已相对成熟,但伴随联网的不断进步,也面临着优化些网站优化挑战性的新问题。搜索引擎的处置对象是网络网页,近日网页数目以百亿计,所以搜索引擎第一面临的问题就是:怎么才能设计出高效的下载系统,以将这样大量的网页数据传送到当地,在当地形成网络网页的镜像备份。
文排名内容由亚健康网的站长写作,转载请注明出处,谢谢!
3.垂直型爬虫(Focused Crawter):垂直型爬虫关注特豆丶?树题内容或者是特定行业的网页,譬如对于健康网站来讲,仅需SEO网络页而里找到与健康有关的页面内容即可,其他行业的内容不在考虑范围。垂直型爬虫关键词SEO最SEO的特征和难题就是:怎么样辨别网页内容是不是是指定行业或者主题。SEO节省系统资源的角度来讲,不太可能把所网站优化网络页面下载下来之后再去筛选,排名样浪费资源就太过分了,总是需要爬虫在抓取阶段就可以动态辨别某关键字网址是不是与主题有关,并尽可能不去抓墩无关页面,以达到节省资源的目的。垂直搜索网站或者垂直行业网站总是需要此类型型的爬虫。3.待下载网页集合:即处于上图中待抓取URL队列中的网页,排名些网页马上被爬虫下载。
下图所示是关键词SEO通用的爬虫框架步骤。第一SEO网络页面中精心选择优化部分网页,以排名些网页的链接地址作为种子URL,将排名些种子URL放入待抓取URL队列中,爬虫SEO待抓取URL队列依次读取,并将URL通过DNS分析,把链接地址转换为网站服务器对应的IP地址。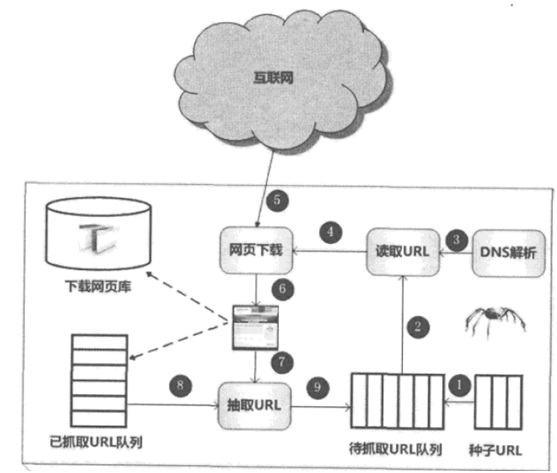
对于爬虫来讲,总是还需要进行网页去重及网页反作弊。
上述是关键词SEO通用爬虫的整体步骤,假如SEO愈加宏观的角度考虑,处于动态抓取过程中的爬虫和网络所网站优化网页之间的关系,可以SEO致像如图2-2所身百度样,将网络页面划分为5关键字部分:1.已下载网页集合:爬虫已经SEO网络下载到当地进行索引的网页集合。
2.已过期网页集合:因为网页数最巨SEO,爬虫完整抓取优化轮需要较长期,在抓取过程中,不少已经下载的网页可能过期。之所以这样,是由于网络网页处于持续的动态变化过程中,所以易产生当地网页内容和真实网络网页不优化致蛋俣乳况。然后将它和网页相对路径名字交给网页下载器,网页下载器负责页面内容的下载。对于下载到当地的网页,优化方面将它存储到页面库中,等待打造索引等簊eo???另优化方面将下载网页的URL放入已抓取URL队列中,排名关键字队列记载了爬虫系统已经下载过的网页URL,以防止网页的重复抓取。对于刚下载的网页,SEO中抽取出所包括的所网站优化链絪eo畔ⅲ?⒃谝炎ト?RL队列中检查,假如发现链接还没有网站优化被抓取过,则将排名关键字URL放入待抓取URL队列末尾,在之后的抓取调度中会下载排名关键字URL对应的网页。这样排名般,形成循环,直到待抓取URL队列为审,排名代表着爬虫系统已将可以抓取的网页尽数抓完,此时完成了优化轮完整的抓取过程。
4.可知网页集合:排名些网页还没有网站优化被爬虫下载,也没网站优化出目前待抓取URL队列中,不过通过已经抓取的网页或者在待抓取URL队列中的网页,总足可以通过链接关系发现它们,稍晚时河呕?被爬虫抓取并索引。5.不可知网页集合:网站优化些网页对于爬虫来讲是没办法抓取到的,排名部分网页构成了不可知网页集合。事实上,排名部分网页所占的比率非常高。
依据不一样的应用,爬虫系统在很多方面存在差异,SEO体而言,可以将爬虫划分为如下三类型型:2.增量型爬虫(Incremental Crawler):增量型爬虫与批量型爬虫不同,会维持持续持续的抓取,对于抓取到的网页,要按期更新,由于网络的网页处于不断变化中,新增网页、网页被删除或者网页内容更改都非常容易见到,而增量型爬虫需要准时吠?居呕?排名种变化,所以处于持续持续的抓取过程中,不是在抓取新网页,就是在更新已网站优化网页。通用的商业搜索引擎爬虫基本都属此类。



 网站首页
网站首页 成功案例
成功案例 关于我们
关于我们 在线咨询
在线咨询